
Google DeepMind 近日正式发布了 Gemini Robotics-ER 1.6。作为其“具身推理”(Embodied Reasoning)模型的最新升级版,这次更新旨在为机器人注入那份在物理世界中极为罕见、却又至关重要的“常识”。新模型显著提升了机器人观察、理解以及与周围环境互动的能力,让机器人不再只是机械地执行指令,而是真正开始对任务进行“思考”。
Gemini Robotics-ER 1.6 的核心升级在于其强化的视觉与空间感知能力,其中最具代表性的便是“指引”(pointing)功能。如果你要求它在杂乱的工作台上寻找某个特定工具,该模型现在能精准地识别、计数并定位目标,同时自动过滤掉无关的干扰物。这不仅仅是“找东西”那么简单,它为更复杂的空间逻辑奠定了基础——比如规划完美的抓取路径,或者理解“把扳手放进工具箱”这类涉及物体关系的指令。该模型甚至能根据约束条件进行推理,例如挑出所有能塞进特定容器的小物件。
此外,该模型还攻克了机器人学中的一个顽疾:判断任务何时真正完成。得益于先进的多视角推理能力,Gemini Robotics-ER 1.6 可以融合来自多个摄像头(例如头顶视角和手腕视角)的实时视频流,从而构建出完整的场景图像。这有效地避免了机器人因为某个物体被暂时遮挡而陷入死循环,或者导致任务失败。
为什么这很重要?
这次更新绝非简单的性能微调,而是在构建机器人自主性的底层逻辑。能够读取模拟仪表、融合多路摄像头信号、理解复杂的空间关系,正是区分“工厂机械臂”与“实用型实地机器人”的关键所在。根据 DeepMind 的官方公告,这也是他们迄今为止最安全的机器人模型。
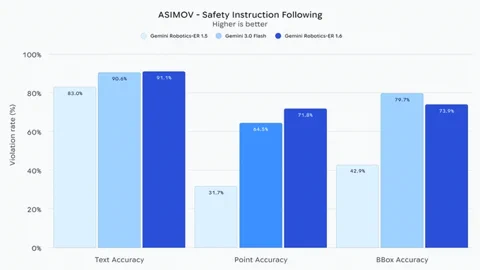
或许最关键的一点是,Gemini Robotics-ER 1.6 在遵守物理安全约束方面展现出了“大幅提升的能力”。它能听懂“避开液体”或“不要搬运超过 20 公斤的物品”等指令。据报告,与基准模型 Gemini 3.0 Flash 相比,它在视频中感知人类受伤风险的准确率提升了 10%。这种对安全性和现实世界推理的专注,是机器人迈向复杂、多变的人类环境并实现可靠运行的关键一步。目前,开发者已可以通过 Gemini API 和 Google AI Studio 使用该模型。
