
当你还以为手机摄像头只能用来拍拍演唱会上那些模糊不清的残影时,研究人员已经把它变成了一个实时 3D 扫描仪。蚂蚁集团 (Ant Group) 旗下的具身智能部门 Robbyant 刚刚开源了 LingBot-Map,这是一个全新的 3D 基础模型,仅凭一段流媒体视频就能重建出精细的大规模环境。最让人惊叹的是,它的运行速度高达每秒 20 帧(FPS),这种效率让传统的摄影测量法(photogrammetry)显得慢如蜗牛。
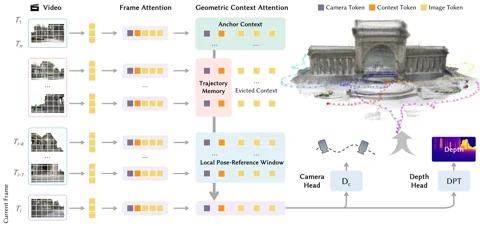
其核心秘诀在于一种被称为几何上下文 Transformer (Geometric Context Transformer, GCT) 的创新架构。这可不只是在视觉问题上随便套个 Transformer 那么简单。GCT 是专门为解决单目(单摄像头)SLAM 系统中的致命伤——“漂移”而设计的。它巧妙地通过三种并行注意力机制来管理几何信息:用于稳定坐标定位的锚点上下文(anchor context)、用于处理精细细节的局部位姿参考窗口(local pose-reference window),以及用于修正长距离误差的轨迹记忆(trajectory memory)。这使得 LingBot-Map 能够处理超过 10,000 帧的序列,且根据 Robbyant 的说法,其精度“几乎保持不变”。该项目目前已在 GitHub 上线。超链接:Robbyant/lingbot-map
坦白说,官方给出的性能数据相当惊人。在极具挑战性的 Oxford Spires 数据集上,LingBot-Map 的绝对轨迹误差(ATE)仅为 6.42 米,比之前的顶级流媒体处理方法提升了近 2.8 倍。它甚至超越了一些成熟的离线方法,而后者通常拥有可以一次性处理所有图像的“上帝视角”。在 ETH3D 基准测试中,它跑出了 98.98 的 F1 分数,以超过 21 个百分点的巨大优势碾压了第二名。如果你对那些“硬核”的技术细节感兴趣,arXiv 上的论文已经披露了完整的技术方案。超链接:Read the paper on arXiv
为什么这很重要?
LingBot-Map 的出现标志着“空间智能”向平民化迈出了重要一步。通过消除对昂贵的激光雷达(LiDAR)或复杂多摄像头阵列的依赖,它为机器人、自动驾驶和增强现实(AR)实现低成本、高性能的 3D 感知铺平了道路。这不仅仅是为了生成漂亮的投影点云,更是为了让机器具备对物理世界持续、实时的理解力。作为一种“3D 基础模型”,它是 AI 进化大趋势中的一部分:未来的 AI 不再仅仅是处理文字或图片,而是要在复杂、无结构的现实环境中进行感知、导航和交互——这正是具身智能(Embodied AI)未来的基石。
