如果你觉得当前机器人领域最大的新闻是某台双足机器人终于学会了走路不摔跤,那你的关注点可能放错地方了。一场远比硬件迭代更具震慑力的变革,正悄然发生在代码日志与数据流之间,而非仅仅在实验室的无尘间里。这场革命就在我们眼皮子底下发生——在 Hugging Face 平台上,开源数据的指数级大爆发正在重塑整个行业。
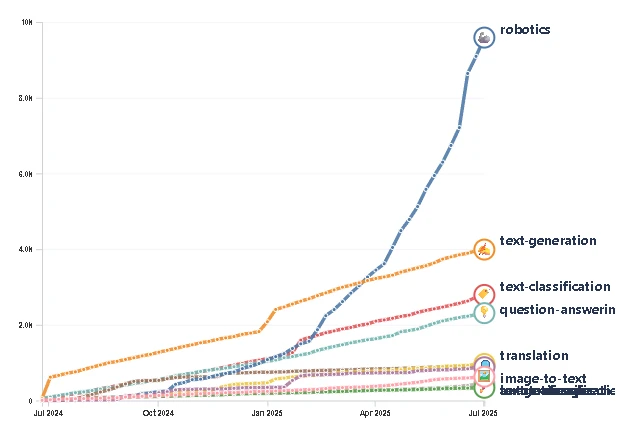
长期以来,大语言模型一直以整个互联网的公开文本为食,而机器人领域却始终处于“数据饥渴”状态。机器人无法仅靠文字进化,它们需要从混乱、随机的物理世界中学习:视频流、关节运动指令、传感器反馈,以及最重要的——失败的教训。在过去,这些珍贵的数据被机器人公司视为“压箱底”的核心资产,锁在私有的保险库里。但现在,那个时代已经彻底终结。仅在过去一年,Hugging Face 上的机器人数据集数量就从 1,145 个飙升至近 27,000 个。高达 2,400% 的涨幅,让机器人品类在短短三年内从第 44 位跃升至榜首,直接碾压了仅有 5,000 个数据集的文本生成类别。
数据大爆发:物理世界的“寒武纪”
这绝非一众爱好者的自嗨。由技术分析师 Pierre-Alexandre Balland 绘制的图表清晰地展示了机器人共享知识的“寒武纪大爆发”。这些数据经过严格筛选,仅包含下载量超过 200 次的数据集,这意味着这个庞大的库正被活跃地用于实验和模型训练,而非躺在服务器里吃灰。

这场激增是多重因素共同催化的结果:更廉价的存储成本、更高效的工具链,以及 AI 圈的开源精神终于渗透进了硬件领地。Hugging Face 等平台极大地降低了分享门槛,构建起一个五年前还无法想象的协作生态。像 LeRobot 这样的项目正致力于标准化数据格式和工具,让每个人都能轻松地为全球机器人大脑贡献力量,并从中获益。
谁是新的“数据寡头”?
究竟是谁在打开泄洪闸?你可能熟知 NVIDIA 的 GPU,但它正迅速成为机器人数据领域的霸主。仅在 2025 年,NVIDIA 的开源数据集下载量就突破了 900 万次。其用于 Isaac GR00T 通用机器人模型微调的数据集,以 790 万次的年下载量傲视全场。这绝非单纯的技术情怀,而是一次精妙的战略布局:通过构建整个行业的基础设施,确保其硬件始终处于生态系统的圆心。
但在这一赛道上,NVIDIA 并不孤单。数据贡献者名单读起来就像一份全球 AI 势力的“名人录”:
- 上海人工智能实验室 (Shanghai AI Lab) 紧随其后,下载量达到了惊人的 760 万次。
- Hugging Face 官方发起的项目贡献了 140 万次下载。
- 学术高地如斯坦福视觉与学习实验室 (SVL) 贡献的数据集下载量超过 71 万次。
- 其他重要玩家还包括 AgiBot(远征)、Yaak AI、AllenAI,甚至包括 Unitree Robotics(宇树科技)这样的硬件制造商。

为什么这才是真正的革命?
几十年来,机器人技术的进步一直被一个残酷的现实所阻碍:每个实验室都在“重复造轮子”。要让机器人学会抓取一个杯子,需要顶尖博士团队、定制化硬件以及数千小时艰苦的数据采集。结果呢?造出来的机器极其脆弱且高度特化,只要你把杯子往左挪动两厘米,它就会陷入瘫痪。
而开源数据范式正彻底粉碎这一瓶颈:
- 准入门槛的崩塌: 一家拥有天才算法的初创公司,不再需要数千万美元的硬件投入才能起步。他们可以直接下载来自数十种不同机器人、不同环境的 TB 级真实世界数据,来训练和验证自己的模型。
- 基准测试的加速: 有了共享数据集,整个行业终于可以在同一条起跑线上同台竞技。它能帮我们拨开营销号的迷雾,真正筛选出那些在复杂、混乱的现实环境中具有泛化能力的算法。
- 飞轮效应的开启: 更多高质量数据催生更强大的基础模型;更强大的模型支撑起更复杂的应用;而这些应用反过来又会产生更多、更有趣的数据。这个良性循环,才是将机器人从实验室推向千家万户的真正引擎。
未来机器人的胜负手,将不再取决于谁拥有最光鲜亮丽的硬件,而在于谁植根于最丰富、最多元的数据生态。当人形机器人的“热舞视频”在社交媒体上收割流量时,这些悄无声息、呈指数级增长的共享数据集,才是正在铺设的真正基石。那场曾经彻底改变软件行业的开源革命,终于降临到了物理世界。这场变革,正通过每一个数据集,重塑我们的未来。